`
<title>🚨正则式</title>
<style>
* {
margin: 0;
padding: 0;
}
.b {
white-space: nowrap; /* 防止换行 */
overflow: hidden; /* 隐藏溢出内容 */
text-overflow: ellipsis; /* 添加省略号表示溢出 */
display: inline-block; /* 使其适应内容宽度 */
font-family: KaiTi;
font-size: 24px;
color: #00e500;
}
.highlight {
color: red;
font-weight: bold;
}
.video-container{
display: flex;
justify-content: right;
align-items: center;
height: 100vh;
}
body {
background-color: #282A36;
padding-top: 60px; /* 根据工具栏的高度调整 */
color: #f5f5f5;
line-height: 1.6;
margin-left: 350px;
margin-right: 200px; /* 根据目录宽度调整 */
font-family: Arial, sans-serif;
counter-reset: section;
display: flex;
flex-direction: column;
align-items: flex-start; /* 所有内容左对齐 */
}
h1, h2, h3 {
color: #4592af;
margin-left: 2px;
white-space: nowrap; /* 防止换行 */
overflow: hidden; /* 隐藏溢出内容 */
text-overflow: ellipsis; /* 添加省略号表示溢出 */
margin-top: 2px;
margin-bottom: -1px;
display: block; /* 确保是块级元素 */
font-size: 24px; /* 根据需要调整 */
}
#toc {
position: fixed;
top: 5px;
left: 5px;
max-height: 90vh; /* 设置最大高度为视口高度的80% */
max-width: 45vh;
overflow-y: auto; /* 添加垂直滚动条 */
background-color: rgba(40, 42, 54, 0.9); /* 半透明背景 */
padding: 20px;
border-radius: 5px;
box-shadow: 0 0 1px rgba(0, 0, 0, 0.1);
font-size: 14px; /* 根据需要调整 */
}
#toc ul {
list-style-type: none;
padding: 0;
margin: 0;
counter-reset: section; /* 重置计数器 */
}
#toc li {
counter-increment: section;
}
#toc li::before {
content: counter(section) ". ";
color: #FF0000;
}
#toc a {
color: #4592af;
text-decoration: none;
}
#toc a:hover {
text-decoration: underline;
}
body > h2 {
counter-increment: section;
}
body > h2::before{
content: counter(section) ". ";
color: #ff461f;
}
.code {
font-family: monospace;
background-color: #f4f4f4;
padding: 5px;
border: 1px solid #ccc;
white-space: pre-wrap; /* 保持格式 */
}
</style>
</head>
<div id="toc">
<!--<h2>目录</h2>-->
<ul id="toc-list">
<!-- 目录项将由JavaScript生成 -->
</ul>
</div>
【回车】和【换行】
在机械英文打字机上,有一个部件叫"字车"(carriage),每打一个单词,"字车"就前进一格。
当打满一行字符后,打字者就得推动"字车"到起始位置,这时打字机会有两个动作响应:
一是:"字车"被归位(carriage return,回到最左端),这个推动"字车"的动作叫"回车"(carriage return)。
二是:滚筒上卷一行(line feed),以便开始输入下一行。
所以合并起来就是CRLF = Carriage Return & Line Feed。
EmEditor
通常,
CR+LF (\r\n) 被用在 Windows 操作系统中,
CR (\r) 被用在 Macintosh 上,
LF (\n) 被用于 Unix。
\r 回车符
\n 换行符
\r\n\r\n可以匹配Windows下的空白行,因为它将匹配两个连续的行尾标签,而这正是两条记录之间的空白行;
<!-- 添加更多章节 -->
匹配以abc为开头,并且最后一个字母不为数字的字符串:
abc[^0-9]
匹配结果
abcd
\d 数字字符,等价于[0-9]
\D 非数字字符,等价于[^0-9]
abc(\D)*
abcf11we
abcerewsdfsggddd2xss
匹配到数字11和2时,匹配终止
<!-- 继续添加其他章节 -->
匹配一组字符
[ ] 定义一个字符集合
0-9、a-z 定义了一个字符区间,区间使用 ASCI 码来确定,字符区间在 [ ] 中使用。
-只有在[]之间才是元字符,在[]之外就是一个普通字符;
^ 在 [ ] 中是取非操作。
各种语言注释的方法
CSS注释: /* 这是一个CSS注释 */
JavaScript注释:
// 这是一个单行注释
/* 这是一个多行注释 */
AHK注释:
; 这是一个单行注释
/* 这是一个多行注释 */
Bat注释:
rem 这是一条注释
:: 这也是一条注释
HTML注释:
匹配邮箱
\w+@(\w+\.)+\w+
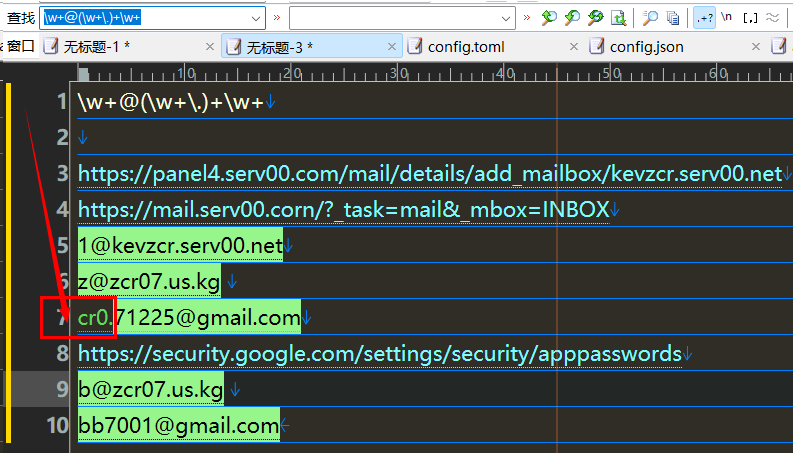
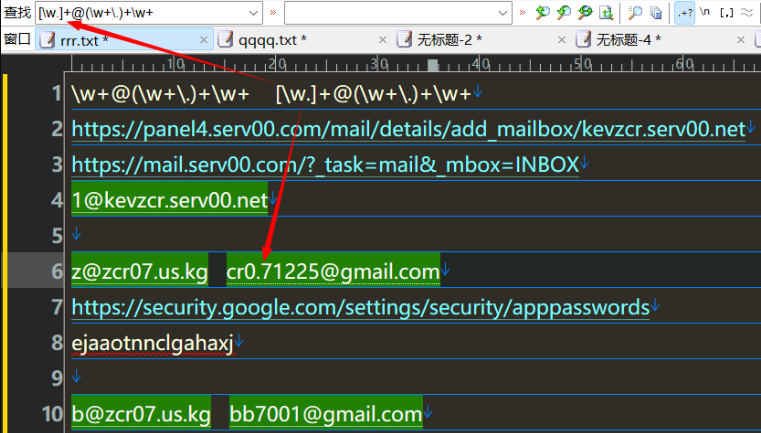
[\w.] 匹配的是字母数字或者 '.' ,在其后面加上 + ,表示匹配多次。在字符集合 [ ] 里, '.' 不是元字符;
* 和 + 都是贪婪型元字符
a.+c

*?、+? 和 {m, n}?懒惰型元字符
a.+?c

匹配//开头的行 注意:可能有空格
^\s*\/\/.*$

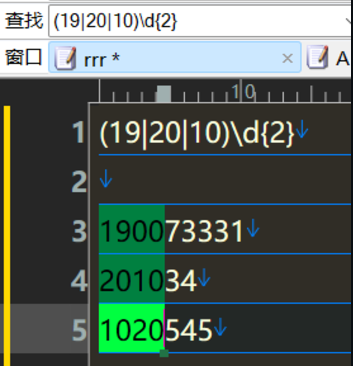
匹配19 20
19|^20|^10

匹配19 20并且后面带2位数字
(19|20|10)\d{2}
</p>
匹配IP地址 错误的方法
(\d+\.)+\d+

匹配IP地址 正确的方法
((25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)


匹配方法
((25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)
查找出 @ 字符后
(?<=@).+

查找出 @ 字符后含-号
(?<=@)\w+-*(\.*\w+)*

查找出 @ 字符后
(?<=@)\w+(\.\w+)*

查找出 @ 字符前含-号
\w+[-\w]*(?=@) ..... \w+-*\w+(?=@)

查找出 @ 字符前
\w+(?=@)

筛选IPv6
(\w+:)+(:+)\w+:\w+

指代法5
查找(tom|jerry)替换为\u$1

指代法4
查找(\w)(\w{2})(\w)替换为$1\U$2\E$3


筛选Html
<(\w+)*.*>.*?<无/\1>

指代法2
<(\w+)*>.*?<无/\1>

指代法1
(\d{3})(-)(\d{3})(-)(\d{4}) 替换为 $5+$1

本后2个以上字符
(?<=本).{2,}

查找出 @ 字符后
(?<=@).+
标点后换行
([[:punct:]])或 ([[:punct:]|=¥]) | \1\n

多空格变单空格
([[:space:]])+ || 单空格 \s+

所有或指定单词大小写 首大写
(THE | fox) || \U$1



改变位置
\b(\w+)\s(\w+)\s(\w+)\s(\w+)\b || $2 $1 $4 $3

多行合并
(?<=[^[:punct:]])\n|^\s+

匹配手机号
1[3-8]\d{9}

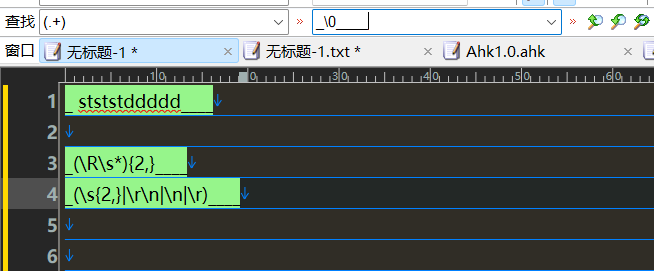
行后加空行 删除空行(用筛选)
(.+) || \1\n


每行前后添加内容
.+ | \[\0]#dd


每行行首添加打开的文件名
.+ | $(FilenameEx)\0\n 注:F和E必须大写

文件夹内的所有TXT文件都加上前后缀
.+ | $(FilenameEx)\0\n"这是A"





匹配第1个数字
\G\d+

匹配特定字符如@后的内容
.+?@\K.+ \K:重置匹配的起始位置

非捕获组
非捕获组(?:^.*?@+)与捕获组(^.*?@+)两者的区别

匹配IPV6节点 全匹配
(\w+:+)+(\w+)+

匹配IPV6节点 不全
(\w+:)+(:\w+)+

匹配[ ]内的字符
\[\K.+(?=\])

匹配最后一对括号内的内容
.*(?<=\()\K.+(?=\))

匹配所有括号内的字符
\(\K.+?(?=\))


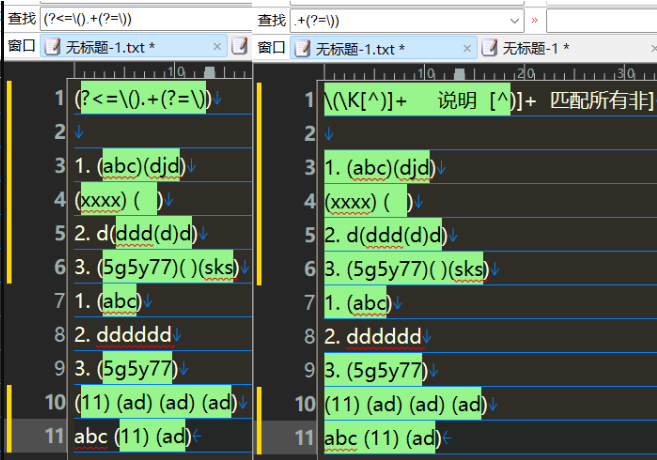
匹配正确的字符,同时如果括号成对也匹配
(\()?abc(?(1)\))

\b\b单词边界
(\()?\bab\b(?(1)\))

跳过规定字符匹配其它
(\d+)(?=-)|(?<=-)(\d+)

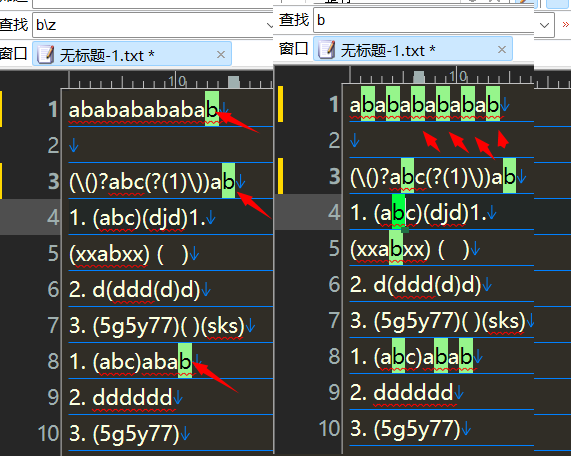
匹配末尾
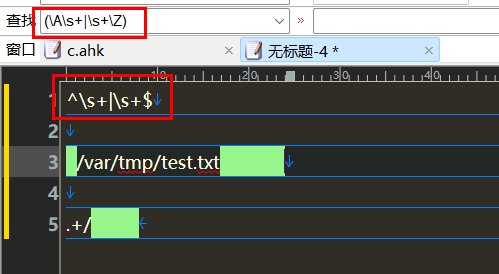
b\z
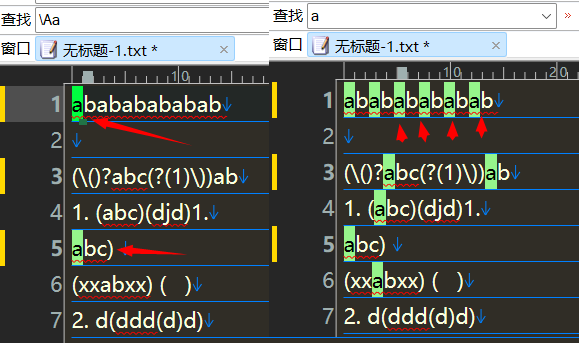
匹配开始
\Aa
单词边界
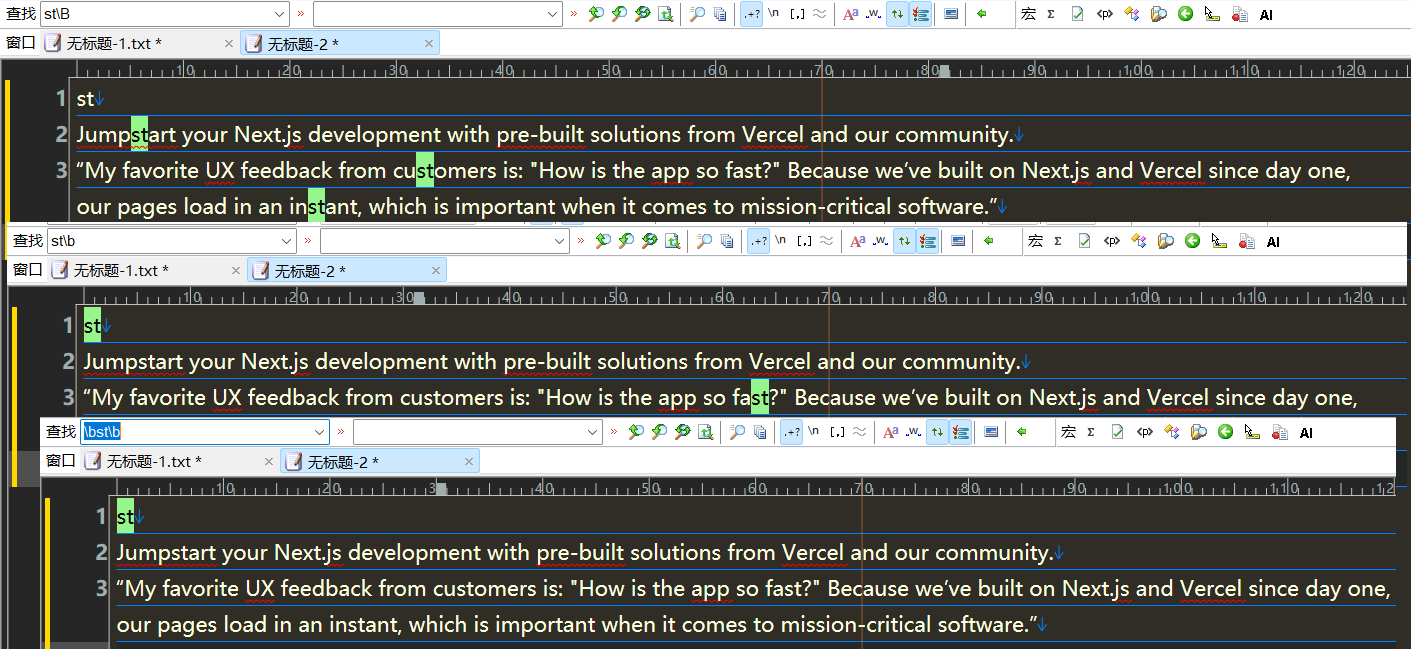
st\B
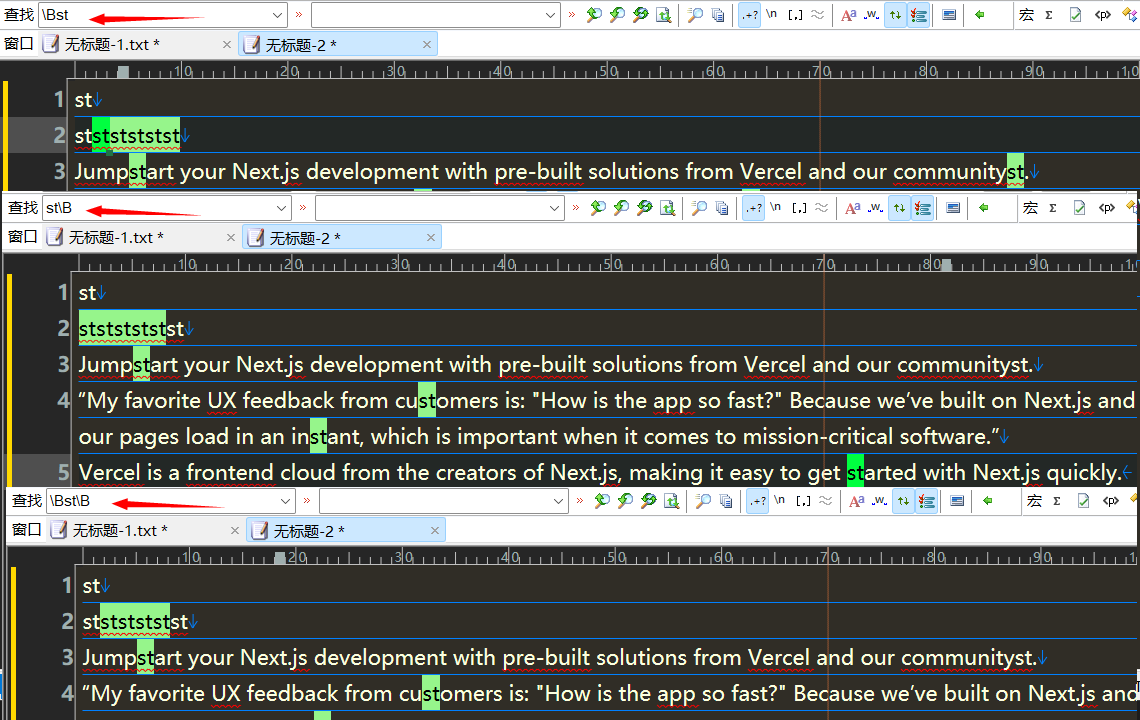
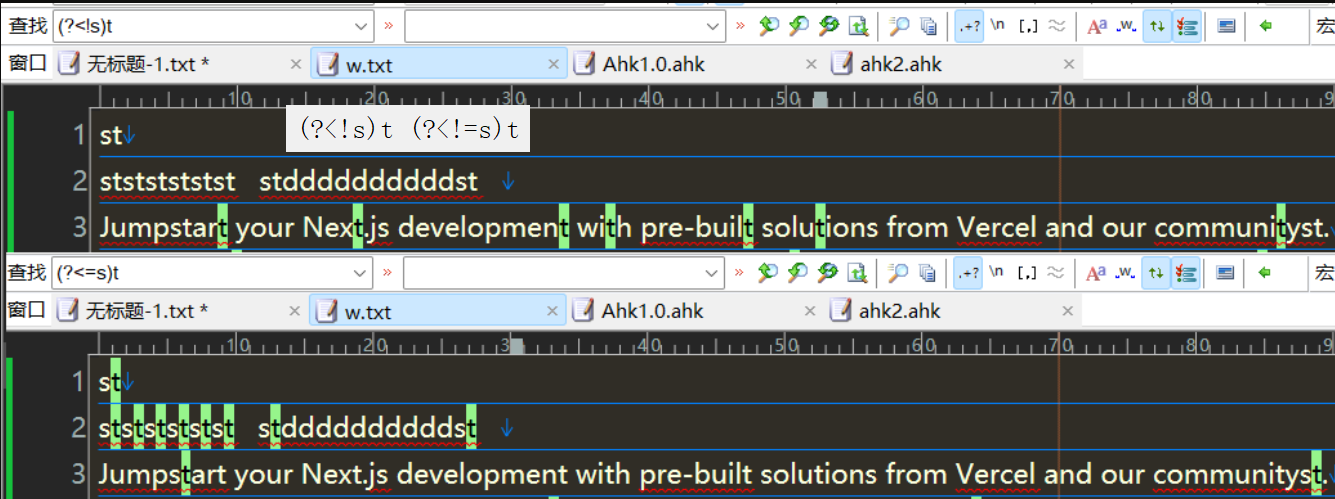
匹配t的左边不是s,是s
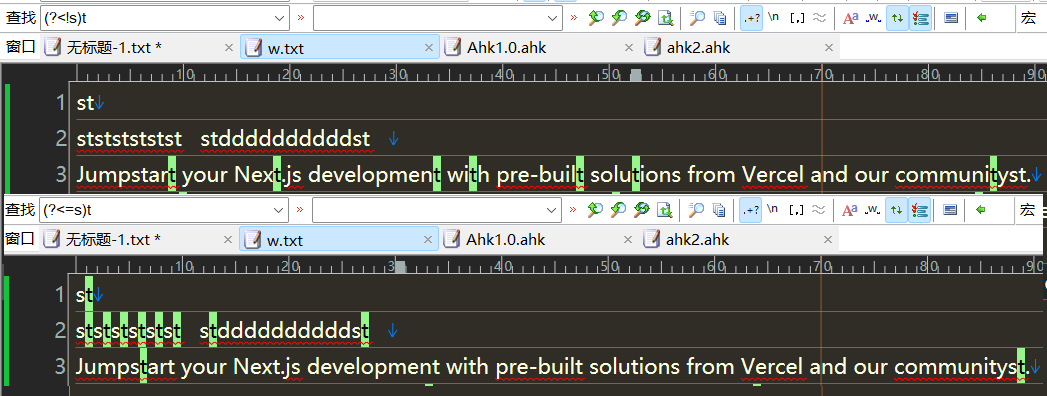

匹配s的右边不是t,是t
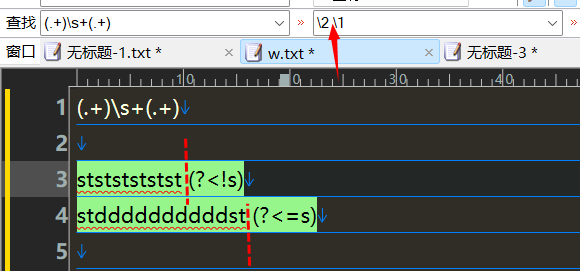
将以空格分隔的前后调换
(.+)\s+(.+)
数字的左右边界
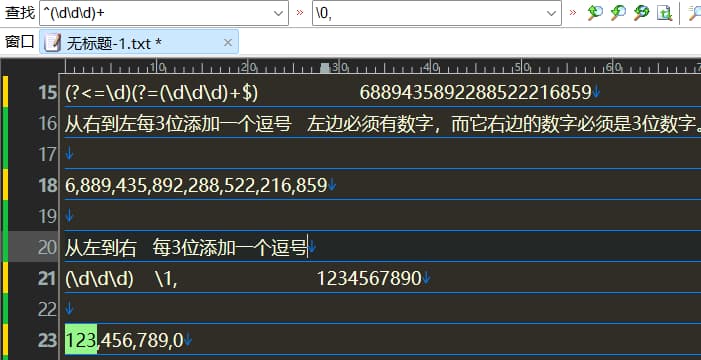
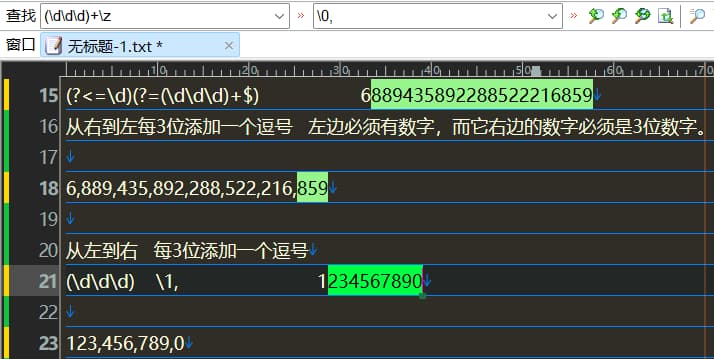
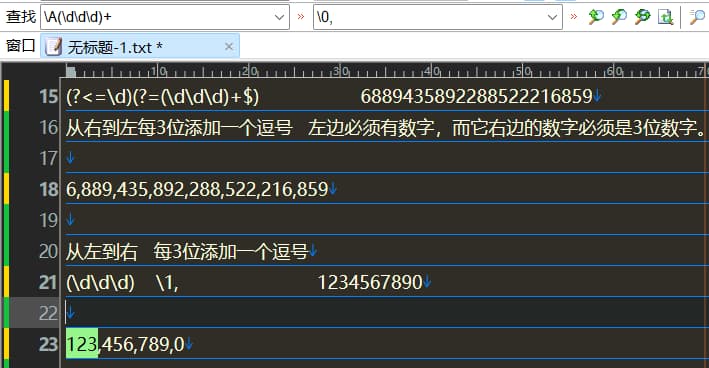
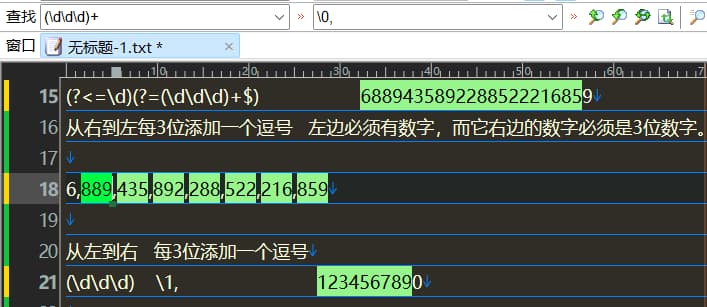
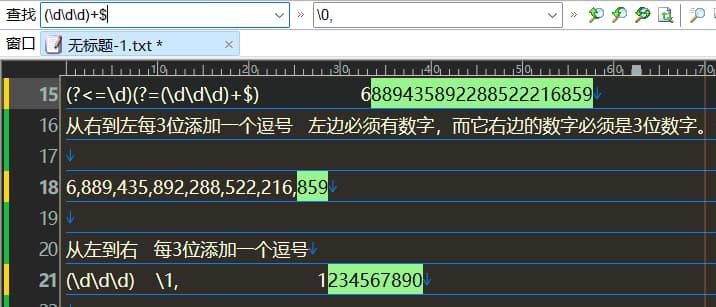
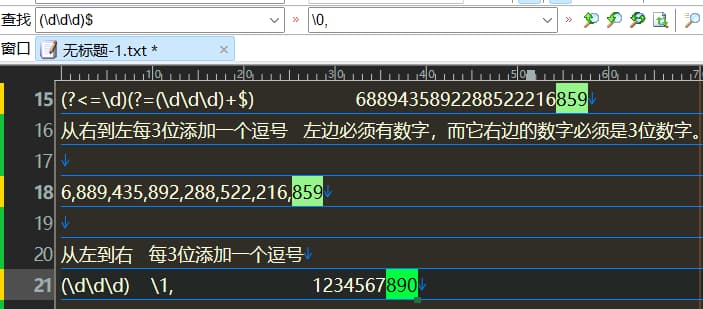
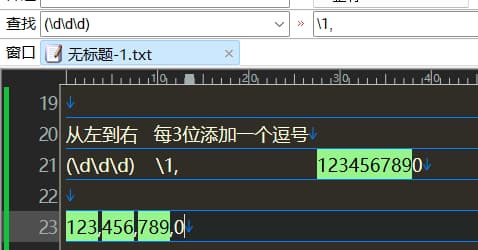
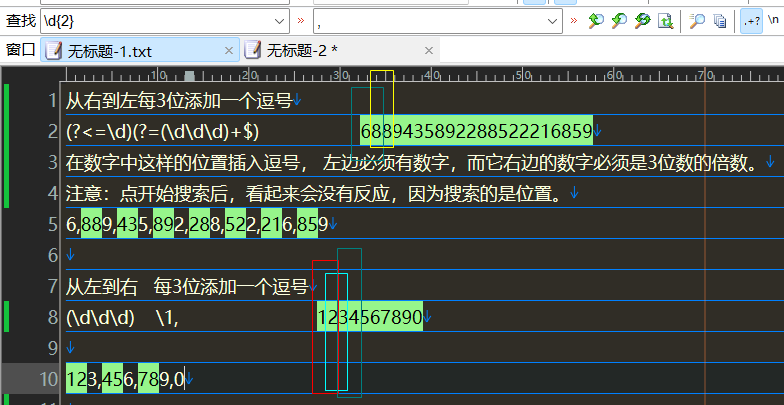

从右向左每3位加一个逗号
(?<=\d)(?=(\d\d\d)+$)
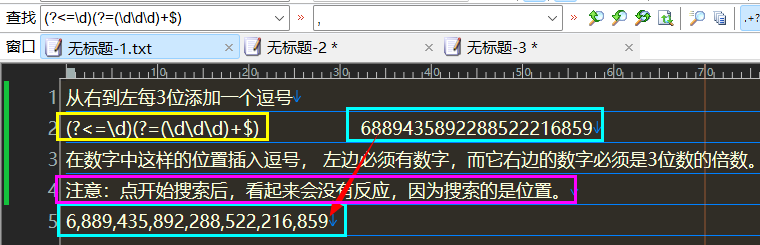
匹配时间
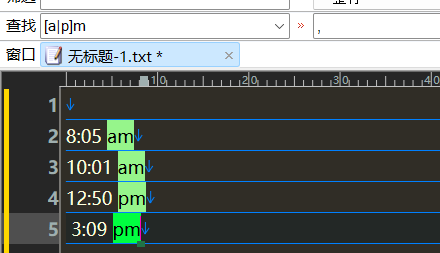
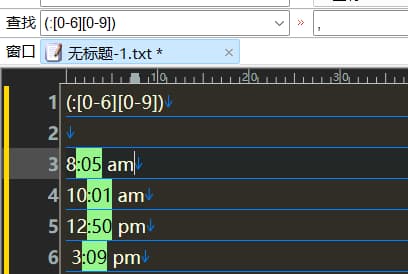
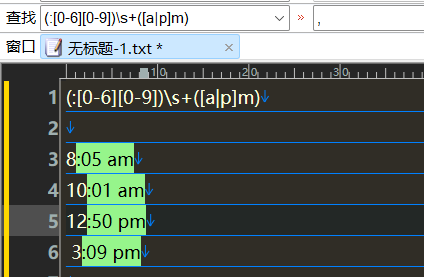
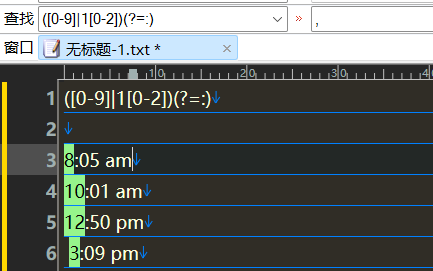
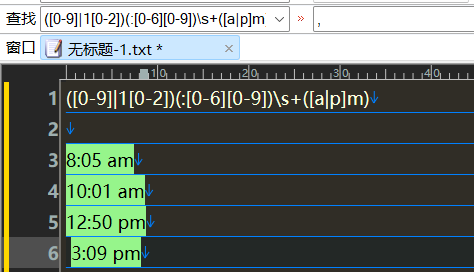
</p>
多空格替换为单空格或无
[\s\r\n]+
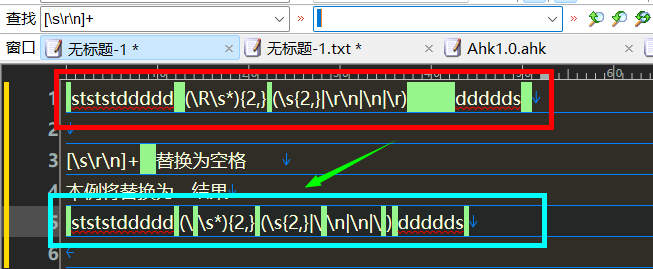
删除空行 1
^[\s\t]*\n
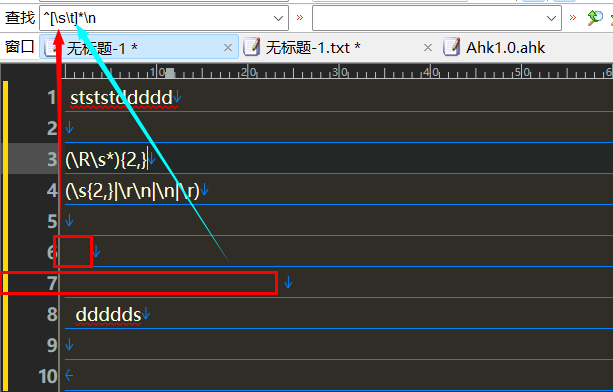
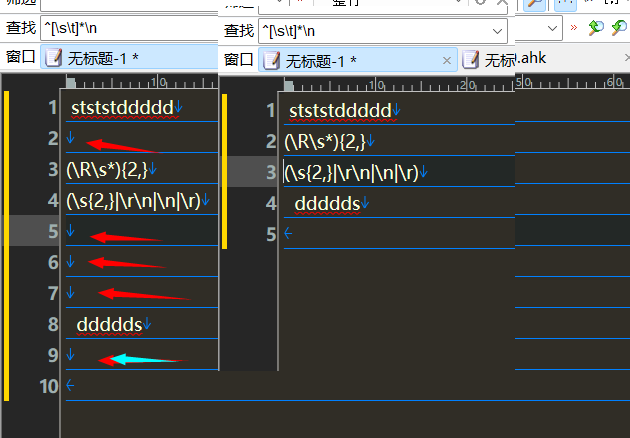
删除空行 2
^(\s*)$\n
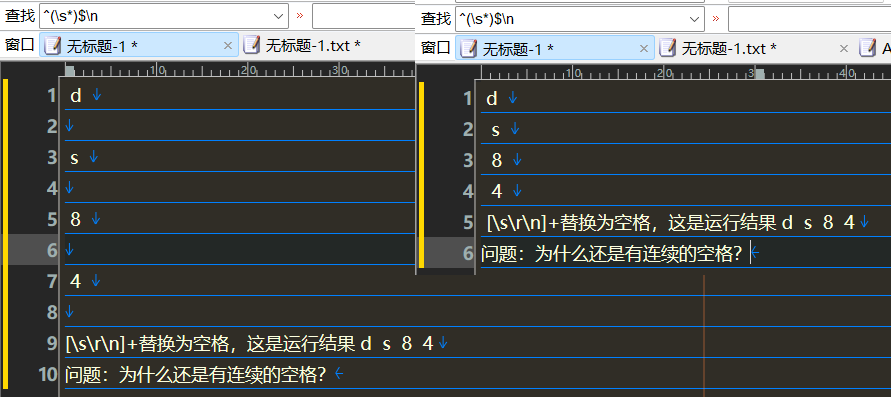
多行合并为1行
[\s\t]*\n
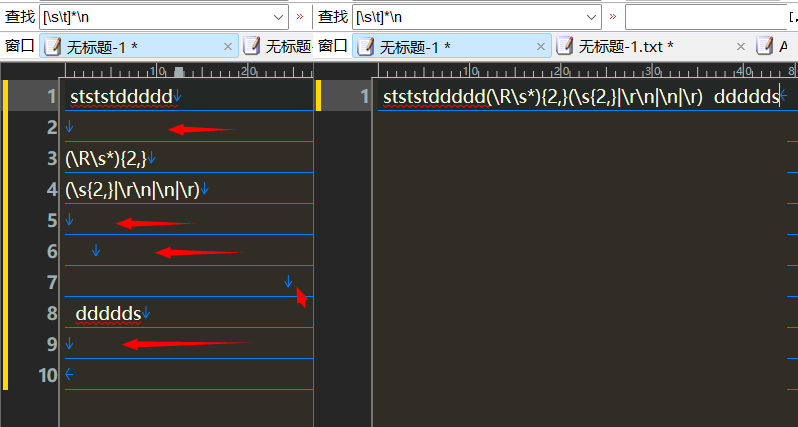
首尾空白字符
^\s+|\s+$
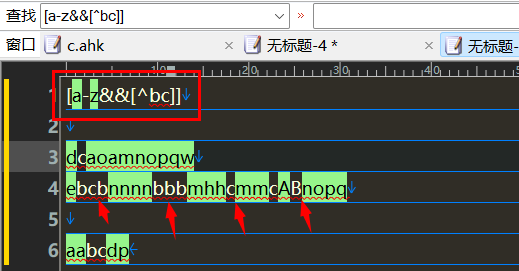
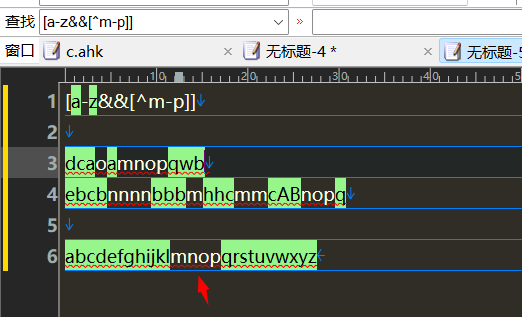
匹配a到z,排除b,c
[a-z&&[^bc]]


Mouselnc 框选ORC

`